Digital Filter Design
Simple FIR Lowpass Filter
Let's design an FIR lowpass filter
First, some notation:
x(n)is the nth sample of input,y(n)is the nth sample of output. Amplitude of sample is assumed -1..1Filter equation:
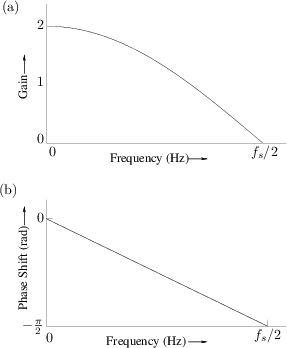
y(n) = (x(n) + x(n - 1)) / 2Why is this a low-pass filter? For higher frequencies if sample
x(n)is positive samplex(n-1)will tend to be negative, so they will tend to cancel. For lower frequencies the samplex(n)will be close tox(n-1)so they will reinforceThis filter is kind of bad: the frequency response doesn't have much of a "knee" at all
On the other hand, this filter is stupidly cheap to implement, and has very little latency: the output depends only on the current and previous samples
{kind=link}
"Higher Filter Orders"
One way to improve a filter is to cascade copies
Filter functions multiply, but it gets a little weird
Common in analog, but almost never in digital
Wider FIR Filters
Normally, you want a much sharper knee
To get that, you typically use more of the history
For standard FIR filters, it is common to use thousands of samples of history
General FIR filter:
$$ y[i] = \frac{1}{k} x[i-k \ldots i] \cdot a[k \ldots 0] $$
So \(k\) multiplications and additions per sample
Now the cost is greater, and the latency is higher, but the quality can be very good
Where do the coefficients \(a\) come from?
Inversion, Reversal, Superposition
Why the obsession with lowpass? Because we can get the other kinds "for free" from the lowpass
Inversion: Negate all coefficients and add 1 to the "center" coefficient — this flips the spectrum, so high-pass
Reversal: Reverse the order of coefficients — this reverses the spectrum, so high-pass
Superposition: Average the coefficients of two equal-length filters — this gives a spectrum that is the product of the filters. If one is low-pass and the other high-pass, this is band-notch. We can then invert to get bandpass.
Convolution
A filter can be thought of as a convolution of the input signal: sum of possibly delayed weighted inputs
Convolution is probably out of scope for this course, but pretty cool
Interestingly, multiplication in the frequency domain is convolution in the time domain. This means that we can use a DFT as a convolution operator if we like
FIR "Windowing" Filters
In general, simplest low-pass filters: take a "window" of past samples, then "round off the corners" by multiplying by some symmetric transfer function
There are many window functions, each with their own slightly different properties as filters: simple things like triangular, plausible things like cosine, and weird things like Blackman, Hamming, Hanning
Note that windowing is also how we deal with edge effects of DFT: we make the signal have period equal to the DFT size by applying a window, but this also low-passes and changes the signal
FIR Chebyshev "Remez Exchange" Filters
There's a fancy mathematical trick for approximating a given desired filter shape with high accuracy for a given filter size
Involves treating filter coefficients as coefficients of a Chebyshev Polynomial, then adjusting the coefficients until maximum error is minimized
Probably not something you want to do yourself, but there are programs out there that will do it for you
IIR Filters
Can get much better response per unit computation by feeding the filter output back into the filter (?!)
In some applications, a 12th-order IIR filter can replace a 1024th-order FIR filter
Design of these filters really wants a full understanding of complex analysis, outside the scope of this course
Fortunately, many standard filter designs exist: Chebyschev, Bessel, Butterworth, Biquad, etc
Basic operation is the same as FIR, except that you have to remember some output:
y(n) = (1/(k+m)) (x(n-k … n) ∙ a(k … 0) + y(n-m-1 … n-1) ∙ a(0 … m))Always use floating point, as intermediate terms can get large / small
Really, just look up a filter design and implement it: probably too hard to "roll your own"