Digital Sound
Discretization
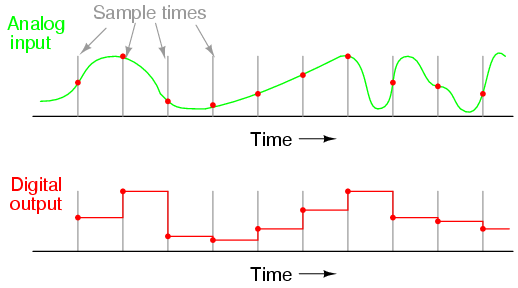
Idea: Discretize analog signal in time and space as "samples"
Simplest to use uniform sampling time (discretization in time), fixed-size binary representation of sample values (discretization in amplitude)
- High sampling rates and lots of bits is more accurate, but "wasteful" for slowly-varying or low-amplitude signals
This is often called "Pulse Code Modulation" (PCM), and is the basis of most "time-domain" digital representations of sound
Usually PCM is "Linear Pulse Code Modulation" (LPCM): the binary amplitude values are interpreted directly. Sometimes a function is used to transform the sample values (e.g. A-law, μ-law) to try to use fewer bits per sample with a decent representation: see below
{kind=link}
Advantages of Discretization
Somewhat noise-immune: small variations in amplitude will be deliberately lost by the process
Can be perfectly stored, transmitted and reproduced (all loss is up-front)
Can be manipulated with a computer: simple compared to analog
Audiophiles hate it
Nyquist Limit
Sound is a fundamentally frequency-domain (sum of sinusoids) thing: PCM treats it as time-domain
A particularly striking example of this is the "Nyquist Limit"
To make PCM work well, we need to ensure that we don't try to represent signals that vary quickly relative to the sampling rate
Specifically, we need to ensure that frequencies above half the sample rate are not present in the underlying signal (this is a strange way of putting things, but the math checks out)
We will return to this topic throughout the course
PCM Representation
Sound is represented as sequence of samples: numbers
There is some specified sample rate in samples per second: note that samples per second is 2× max frequency in Hz, because Nyquist
For the human frequency range, 44100 sps (22050 Hz) is more than adequate
Typical low-end music stuff will run at 24000 sps (12000 Hz) or the analog equivalent bandwidth
Voice can be adequately reproduced to be intelligible at 8000 sps (4KHz). This is the Plain Ol' Telephone Line (POTS) standard
For recording / playback, usually fixed-width integers: signed or unsigned
For the dynamic range of human hearing, 16 bits is plenty
Sound is quite intelligible even at 8 bits, especially if encoded / decoded non-linearly on the front and back (A-law, μ-law) to compress louder amplitudes
- POTS, old video games, etc
Units are complicated: usually just normalized to range of values
Internal calculations are different
Sample rate of 96000 sps is not uncommon, to give room for frequency domain calculations at the high end (discussed later in the course)
Floating point samples are really useful for convenience and to avoid overflow in calculations. 0.0..1.0 is common, as is -1.0..1.0.
Raw Storage and Transmission
Stereo (or more), so sample-per-channel, interleaved in the "obvious" way: frames. Frames are typically stored / transmitted sequentially: for a stereo signal
frame0 frame1 frame2 ||sample|sample||sample|sample||sample|sample||…Lots is implicit: Sample rate? Frame size in channels? Frame order? Sample size? Sample endianness? Interpretation of sample bits?
Transmission: Usually these things are specified by some external protocol
Storage: Often many of these things are recorded in a header for flexibility